














HTML
-
The beet armyworm—Spodoptera exigua—is a major migratory insect pest that damages numerous vegetables and is causing increasing economic losses in the agriculture sector, including the industries related to cotton, food crops, and timber (Zheng et al., 2012; Virto et al., 2014; Qiu et al., 2015; Sun et al., 2015). The baculovirus S. exigua multiple nucleopolyhedrovirus (SeMNPV) is a very specific pathogen of S. exigua, hence, it has been developed for use as a bioinsecticide (Virto et al., 2014). Several bioinsecticides, including SPEXIT®(Andermatt Biocontrol, Switzerland), VIR-EX®(Biocolor, Spain), and SPOD-X®(Certis, US) contain SeMNPV.
Viral infections can be divided into acute, persistent, and latent infections. The vast majority viral genes are expressed during the acute infection and, because of the production of progeny virions, the infection spreads within a host and to new hosts (Saffert and Kalejta, 2007). During persistent infections, some viral genes are downregulated by viral or cellular regulatory gene products (Mayer and Ebbesen, 1994). A latent infection is defined as a reversible nonproductive infection of a cell in which the viral genome is present but infectious viruses are not produced except during intermittent episodes of reactivation (Stevens, 1989). During latent infections, viral genomes are maintained in host cells for a long periods with very little or no gene expression, which allows the virus to evade detection by the host immune system (Murillo et al., 2011).
P8-Se301 cells are S. exigua Se301 that are infected with an attenuated version of SeMNPV and the P8-Se301-C1 cell strain is cloned from these persistently infected P8-Se301 cells. P8-Se301-C1 cells harbor a partial SeMNPV genome and they are morphologically similar to Se301 cells but they do not produce viral progeny. The cells are resistant to SeMNPV infection but not to infection by the heterologous Autographa californica multiple nucleopolyhedrovirus (AcMNPV), which is also a baculovirus. It has been suggested that SeMNPV resides in P8-Se301-C1 cells as a latent-like infection, which means that these cells provide a promising experimental system to investigate the mechanisms of baculovirus persistence in insects (Weng et al., 2009).
Herpes simplex virus 1 (HSV-1) can establish lifelong latency in the trigeminal sensory neurons of humans, and the expression of the viral RNA known as latency-associated transcript (LAT) in the absence of the production of viral proteins is believed to play a role in establishing latency (Perng et al., 1996; Thompson and Sawtell, 1997). Therefore, exploring the transcription of SeMNPV genes in P8-Se301-C1 cells may aid the understanding of the molecular mechanism of latent infections.
Recently, Illumina strand-specific RNA sequencing (RNA-Seq)—a newly developed, large-scale, and genome-wide process—has been used for transcriptome analysis and gene discovery. This highlights the potential to use RNA-Seq to cost-effectively obtain large amounts of transcriptome data and then compare the evolution of the genomes of non-model species (Zhao et al., 2014; Slavokhotova et al., 2015; Xu et al., 2015). RNA-Seq has several obvious advantages, such as its cost-effectiveness, its high resolution, and the fact that it has a wide dynamic range of expression levels over which transcripts can be detected (Vogel et al., 2014; Lambirth et al., 2015). In this study, Illumina paired-end sequencing was used to analyze the de novo transcriptomes of S. exigua cells. We compared the transcriptome sequences of P8-Se301-C1 cells and Se301 cells using RNA-Seq and identified ten SeMNPV gene transcripts in the P8-Se301-C1 cells. Moreover, six additional SeMNPV gene transcripts were detected in P8-Se301-C1 cells using 5'/3' rapid amplification of cDNA ends (RACE) analyses. These novel findings provide useful information on the mechanisms of latent infections and superinfection exclusion.
-
Se301 and P8-Se301-C1 cells were cultured at 27 ℃ in Grace's Insect Medium (Invitrogen, Carlsbad, US) supplemented with 10% fetal bovine serum (FBS), penicillin, (100 μg/mL) and streptomycin (30 μg/mL).
-
The total RNA was extracted from the two cell lines using a TaKaRa MiniBEST Universal RNA Extraction Kit (TaKaRa, Dalian, China) according to manufacturer's protocol. The RNA integrity number (RIN) of the total RNA was verified using an Agilent Bioanalyzer 2100 (Agilent Technologies, Santa Clara, CA, US), and the quantity was measured using a NanoDrop 2000 Spectrophotometer.
The total RNA was purified further using an RNeasy Micro Kit (QIAGEN GmBH, Germany) and an RNase-Free DNase Set (QIAGEN). After removing the ribosomal RNA, the remaining RNA was split into short fragments using an RNA fragmentation buffer. The RNA fragments were used as templates to amplify first-strand cDNA using random hexamerprimers, and then the second cDNA strand was synthesized. cDNA libraries of both the Se301 cells and the P8-Se301-C1 cells were created using the double-stranded cDNA. Paired-end sequencing was carried out using the PE125 strategy of the Illumina HiSeq 2500 Sequencing System (Illumina, San Diego, CA, US) at Shanghai Biotechnology Corporation.
-
Before assembly and mapping, the raw RNA-Seq reads obtained from the Se301 and P8-Se301-C1 cDNA libraries were processed using the ShortRead package to filter out low-quality nucleotide sequences, adapters, and PCR primer sequences. Reads with a length shorter than 35 nt or with at least 2 ambiguous nucleotides (i.e., those which could be any type of nucleotide) were removed. The resulting cleaned reads were mapped to the SeMNPV genome to screen out the SeMNPV gene transcripts. The cleaned reads were assembled as primary unigenes using the Trinity package with an optimized k-mer length of 25 (Tao et al., 2012; Chen et al., 2014). The primary unigenes were cleaned by removing redundant genes and they were then assembled into a final set of unigenes using CD-HIT software (Yang and Smith, 2013). The cleaned reads were aligned to the final unigenes using the mapping algorithm, FANSe2, and allowing up to 7 mismatched nucleotides (Zhang et al., 2012; Xiao et al., 2014). The final set of unigenes (with at least 10 mapped reads) were considered to be reliably assembled unigenes.
-
Universal Protein (UniProt) is the most comprehensive catalog of protein sequences and functional annotations (Uniprot Consortiums, 2011). In addition, the Gene Ontology (GO) database, the Clusters of Orthologous Groups of proteins (COG) database, and the Kyoto Encyclopedia of Genes and Genomes (KEGG) database are major databases of putative gene functions (He et al., 2012). BLASTX was used to search the UniProt, GO, COG, and KEGG databases for the final unigenes, with an e-value cut-off of 1e-5.
-
RT-PCR was used to verify the SeMNPV gene transcripts from the P8-Se301-C1 cells. A cDNA First Strand Synthesis Kit (SiDanSai, Shanghai, China) was used to reverse transcribe 1 μg of total RNA extracted from the P8-Se301-C1 cells and from the Se301 cells into cDNA. The transcripts of the SeMNPV genes that were detected in the P8-Se301-C1 cells by RNA-Seq were amplified using RT-PCR and Se301 cells were used as a negative control. The specific primers are shown in Supplementary Table 1. Agarose gel electrophoresis was carried out to separate the resulting DNA products, which were then sequenced by Beijing Ruibo (Guangzhou, China).
-
To sequence the full-length of the SeMNPV gene transcripts, the total RNA was extracted from the P8-Se301-C1 cells and RACE analyses were carried out with a SMARTer RACE 5'/3' Kit (Clontech, US). A set of gene-specific primers were designed (Supplementary Table 1) and labelled either GSP (gene-specific primer) or NGSP (nested gene-specific primer) according to the sequence of the RT-PCR products. PCR amplification was carried using the following protocol. Briefly, reaction volumes of 20 μL were prepared containing 5'/3'-RACE-Ready cDNA as the template, primers (0.5 μL of the 10 μM GSP and 2.0 μL of the universal primer mix provided in the kit) and 2×PrimerSTAR Max DNA Polymerase (TaKaRa). The conditions were as follows: 2 min at 94 ℃; 25 cycles of 30 s at 94 ℃, 30 s at 68 ℃, 3 min at 72 ℃; and a final extension at 72 ℃ for 5 min. The products were diluted with water (using a ratio of 1:10) and used as template cDNA for the nested PCR. The nested PCR conditions were as follows: 2 min at 94 ℃; 30 cycles of 30 s at 94 ℃, 30 s at 55 C-60 ℃, 3 min at 72 ℃; and a final extension at 72 ℃ for 5 min. The PCR products were visualized by electrophoresis on a 1% agarose gel and sequenced. Subsequently, the 5' and 3' fragment sequences were assembled to obtain the full-length cDNA sequences of each of the SeMNPV genes.
Cell culture
RNA extraction, cDNA synthesis, and Illumina sequencing
Sequence statistics, de novo assembly, and mapping
Annotation
Reverse transcription PCR (RT-PCR)
5'/3' RACE analysis
-
A total of 56, 865, 504 raw reads were obtained from the Se301 cells and 54, 569, 296 were obtained from the P8-Se301-C1 cells. After a series of stringent filtering processes, 55, 033, 958 and 52, 784, 058 clean reads were obtained from the Se301 and P8-Se301-C1 cells, respectively (Supplementary Table S2).
-
After primary assembly, we obtained 116, 048 counts with a mean length of 1, 173 nt and an N50 of 2, 137 nt from the P8-Se301-C1 cells and 104, 600 counts with a mean length of 1, 169 nt and an N50 of 2, 145 nt from the Se301 cells (Supplementary Table S3). After further assembly, we obtained 112, 565 counts with a mean length of 1, 093 nt and an N50 of 1, 824 nt from the P8-Se301-C1 cells and 102, 996 counts with a mean length of 1, 082 nt and an N50 of 1, 803 nt from the Se301 cells (Supplementary Table S4). The final set of unigenes from the P8-Se301-C1 cells comprised 24, 731 unigenes (24.33%) that were≥1, 000 nt long and 10, 229 unigenes (10.06%) that were > 2, 000 nt long. The final set of unigenes from the Se301 cells comprised 29, 849 unigenes (28.98%) that were≥1, 000 nt long and 13, 949 unigenes (13.54%) that were > 2, 000 nt long. The distributions of the lengths of the final unigenes from the P8-Se301-C1 and Se301 cells are presented in Supplementary Figure S1.
-
Of the 112, 565 final unigenes from the P8-Se301-C1 cells, 26, 553 (23.6%) were annotated, and of the 102, 996 final unigenes from the Se301 cells, 24, 906 (24.2%) were annotated. The distributions of the BLASTX search (Uniprot database was used) hits for the P8-Se301-C1 and Se301 samples are shown in Figure 1. There were a significant number of hits for the unigenes from both cell lines with species in the order Lepidoptera.

Figure 1. Distribution of the most frequent BLASTX hits (associated with 20 species) for the unigenes from the P8-Se301-C1 (A) and Se301 cells (B). There were a significant number of hits for the unigenes from both cell lines with species in the order Lepidoptera.
The main GO categories were cellular components, biological processes, and molecular functions. The terms associated with the P8-Se301-C1 sample were all from these three main GO categories and comprised 53 functional subcategories) (Supplementary Figure S2). Regarding the cellular components category, the largest proportion of unigenes were assigned to the following subcategories: cells (20.52%), cell part (20.52%), membrane (14.28%) and membrane part (11.48%). The majority of the unigenes in the biological process category were assigned to the metabolic process subcategory (26.57%) and the cellular process subcategory (23.75%). Most of the unigenes in the molecular function category were related to binding (45.90%) and catalytic activity (38.61%), which included genes that encoded kinases, transferases, and hydrolases, many of which are likely to be involved in DNA replication, transcription, and translation.
To assist with the functional classification of the final set of unigenes, information on the functional classification of their homologs in the COG database was explored (Liu et al., 2016). A total of 19, 825 unigenes from the P8-Se301-C1 cells were clustered into 25 COGs (Figure 2). Among them, the signal transduction mechanisms cluster was the largest (8.71%), followed by the general function prediction only cluster (6.75%). The other large clusters were transcription (5.03%), RNA processing and modification (4.48%), posttranslational modification, protein turnover and chaperones (4.40%), cytoskeleton (3.53%) and intracellular trafficking, secretion and vesicular transport (3.01%).

Figure 2. Clusters of orthologous groups (COG) classification of unigenes in P8-Se301-C1 sample.
To identify the biological pathways that are active in the S. exigua cell lines, we mapped the 26, 553 annotated sequences from P8-Se301-C1 cells to those associated with the canonical reference pathways in the KEGG database. In total, 26, 553 unigenes were assigned to 290 known metabolic or signaling KEGG pathways. The top 11 KEGG pathways were metabolic pathways (2041 unigenes), biosynthesis of antibiotics (839), ribosomes (697), biosynthesis of secondary metabolites (687), protein processing in the endoplasmic reticulum (540), microbial metabolism in diverse environments (324), purine metabolism (308), HTLV-I infection (304), the PI3K-Akt signaling pathway (283), spliceosomes (279), and RNA transport (263).
-
After the clean reads from RNA-Seq were aligned with the SeMNPV genome, it was found that ten SeMNPV gene transcripts from the P8-Se301-C1 cells were not identified in the Se301 samples: se5 (unknown function), se7 (me53), se8 (envelope fusion protein), se12 (lef2), se43 (unknown function), se45 (ribonucleotide reductase small subunit), se89 (unknown function), se90 (unknown function), se124 and se126 (DNA binding protein).
RT-PCR was carried out to confirm the presence of the ten SeMNPV gene transcripts in the P8-Se301-C1 cells. The RT-PCR products were distinguished by agarose gel electrophoresis, and fragments of the expected sizes were detected for the P8-Se301-C1 samples, but not for the Se301 samples (Figure 3). The RT-PCR products were further verified by sequencing and by using a BLAST search of the NCBI's Nucleotide Database. All the RNA samples prepared in this study were subjected to RT-PCR with the same primers and the results indicated that there was no DNA contamination.

Figure 3. Ten SeMNPV genes (from the RNA-Seq analysis) verified by RT-PCR. The total RNA was extracted from the P8-Se301-C1 and Se301 cells and cDNAs were constructed. Subsequently, the ten SeMNPV genes were amplified by PCR and visualized on 1% agarose gel (the names of each of the genes are shown above each lane). PCRs were also performed with the RNA samples in place of the cDNA to exclude the possibility of DNA contamination.
-
To further understand the full-length transcripts of the ten SeMNPV genes from the P8-Se301-C1 cells, both 3' and 5' RACE analyses were performed using the total RNA extracts. No gene products were detected in the first round of amplification. However, after the second round of nested PCR using the RACE amplification products, a range of fragment products were observed (Figure 4).

Figure 4. RACE analyses of the 3' and 5' end sequences of the SeMNPV gene transcripts in P8-Se301-C1 cells. (A) 3′end RACE analysis. (B) 5′ end RACE analysis. The total RNA was extracted from the P8-Se301-C1 cells and 5'/3' RACE analyses were performed to determine the nucleotide sequences of the 5' and 3' ends of the SeMNPV gene transcripts. The PCR products were visualized on 1% agarose gel. No gene products were detected in the first round of amplification. However, after a second round of nested PCR on the RACE amplification products, a range of fragment products were observed. H2O were used to as a control.
The fragments of the 3′ and 5′ ends of the gene transcripts were recovered and sequenced, and then the sequences were assembled (along with the sequences from the previous RNA-Seq) into full-length transcripts. The full-length sequences of the transcripts were used to carry out a BLAST search of the NCBI's Nucleotide Database, and six additional SeMNPV gene transcripts from the P8-Se301-C1 cells were identified, including se11 (orf4 PE), se42 (unknown function), se44 (unknown function), se88 (iap-2), se91 (lef-3) and se127 (lef-6) (Figure 5A and Supplementary Figure S3). Thus, in total, sixteen viral gene transcripts that mapped to the SeMNPV genome were identified in the P8-Se301-C1 cells by a combination of RNA-Seq and RACE (Figure 5A), and the genes were found to be located in a disperse region of the SeMNPV genome (Figure 5B).

Figure 5. (A) Chimeric SeMNPV gene transcripts from the P8-Se301-C1 cells. The fragments of the 3' and 5' ends of the ten SeMNPV gene transcripts detected by RNA-Seq (shown on the left) were sequenced and assembled into full-length cDNA sequences. Six more SeMNPV gene transcripts were detected in RACE analyses. The positions of all sixteen detected SeMNPV genes (in green) are shown aligned to the SeMNPV genome. The SeMNPV genes integrate into the host genome and the 3′ or 5′ ends of the SeMNPV gene transcripts (in green) are aligned to the host genome (in yellow). The bar at the top of the figure is marked to show the size of each of the transcripts. (B) Overview of the SeMNPV transcripts from the P8-Se301-C1 cells. The sixteen SeMNPV genes (in green) detected by RNA-Seq and RACE analyses map to the SeMNPV genome (in dark green). The circular map has been modified according to the map of the SeMNPV genome (IJkel et al., 1999).
The full-length sequences of the transcripts showed that the SeMNPV genes are incorporated into the host cell genome. The genes consequently form chimeric fusion transcripts in P8-Se301-C1 cells, and either the 3' or 5' end of each transcript is aligned with the host genome (Figure 5A and Supplementary Figure S3).
The organization of each fusion transcript is as follows (Table 1). (1) The full-length transcript containing the se5 gene maps to the nt positions in the SeMNPV genome at 6190-7713, the 5' end sequence (nt 3-48) aligns to the Bombyx mori akh2 mRNA (nt 26-71) that encodes adipokinetic hormone-2 and the 3' end sequence cannot be aligned to any known sequence in the NCBI's Nucleotide Database. (2) The full-length transcript containing se7 maps to nt 9261-10433 of the SeMNPV genome, the 5' end sequence cannot be aligned to any known sequence and the 3' end sequence (nt 1373-1448) aligns to the B. mori dh40 mRNA (nt 3116-3192) that encodes diuretic hormone 40. (3) The full-length transcript containing se8 maps to nt 12498-14495 of SeMNPV the genome) and the 5' end sequence (nt 12-60) aligns to the B. mori dh40 mRNA (nt 1035-998). (4) The full-length transcript containing se12 (which map to nt 16064-16693 of SeMNPV genome) and the partial sequences of se11 (which map to nt 15817-15852 and nt 15923-16101 of the SeMNPV genome) are transcribed together. The 5' end sequence (nt 5-48) aligns to the B. mori akh2 mRNA (nt 27-71) and the 3' end sequence cannot be aligned to any known sequence. (5) The full-length transcript containing se43 (which maps to nt 42696-43856 of the SeMNPV genome) and the partial sequence of se42 (which maps to nt 42392-42606 of the SeMNPV genome) are transcribed together. Neither the 5' end nor the 3' end can be aligned to any known sequence. (6) The full-length transcript containing se45 (which maps to nt 44408-45394 of the SeMNPV genome) and the partial sequence of se44 (which maps to nt 44305-44312 of the SeMNPV genome) are transcribed together. The 5' end sequence cannot be aligned to any known sequence. (7) The full-length transcript containing se89(which maps to nt 85499-86398 of the SeMNPV genome) and the partial sequence of se88 (which maps to nt 85088-85799 of the SeMNPV genome) are transcribed together. The 5' end sequence cannot be aligned to any known sequence. (8) The full-length transcript containing se124 (which maps to nt 118809-119391 of the SeMNPV genome), the partial sequences of se90 (which maps to nt 86521-86789 of the SeMNPV genome) and se91 (which maps to nt 86788-86860 of the SeMNPV genome) are transcribed together. The 5' sequence (nt 3-50) aligns to the B. mori dh40 mRNA (nt 25-71). (9) The full-length transcript containing se126 (which maps to nt 120802-121788 of the SeMNPV genome) and the partial sequence of se127 (which maps to nt 121816-122307 of the SeMNPV genome) are transcribed together. The 5' end sequence cannot be aligned to any known sequence and the 3' end sequence (nt 1360-1413) aligns to the B. mori sifa mRNA (nt 462-564) that encodes SIFamide.
Transcript size (bp) Harbored SeMNPV genes 5' end sequence 3' end sequence Position in the transcript SeMNPV gene (position in the SeMNPV genome) Position in the transcript Aligned host gene mRNA (position in the host gene) Position in the transcript Aligned host gene mRNA (position in the gene) 1847 nt 106-1634 se5(nt 6190-7713) nt 3-48 B. mori akh2(nt 26-71) nt 1707-1847 No hita 1530 nt 138-1310 se7(nt 9261-10433) nt 1-130 No hit nt 1373-1448 B. mori dh40(nt 3116-3192) 2136 nt 104-2103 se8(nt 12498-14495) nt 12-60 B. mori dh40(nt 1035-998) —b — 978 nt 300-933
nt 55-91
nt 162-229se12(nt 16064-16693)
se11(nt 15817-15852)
se11(nt 15923-16101)nt 5-48 B. mori akh2(nt 27-71) nt 946-978 No hit 1691 nt 348-1511
nt 46-261se43(nt 42696-43856)
se42(nt 42392-42606)nt 1-46 No hit nt 1520-1691 No hit 1118 nt 161-1107
nt 62-70se45(nt 44408-45394)
se44(nt 44305-44312)nt 1-61 No hit — — 1370 nt 488-671
nt 35-489se89(nt 85499-86398)
se88(nt 85088-85799)nt 1-35 No hit — — 1035 nt 407-991
nt 57-323
nt 322-396se124(nt 118809-119391)
se90(nt 86521-86789)
se91(nt 86788-86860)nt 3-50 B. mori adh40(nt 25-71) nt 1007-1035 — 1421 nt 102-1122
nt 1164-1354se126(nt 120802-121788)
se127(nt 121816-122307)nt 1-62 No hit nt 1360-1413 B. mori sifa(nt 462-564) Note: a: The end sequence cannot be aligned to any known sequence in the NCBI's Nucleotide Database.
b: The end sequence is matched to SeMNPV gene.Table 1. The SeMNPV gene-containing full-length transcripts in P8-Se301-C1 cells
Sequence trimming
De novo assembly
Functional annotation
Identification of SeMNPV gene transcripts in P8-Se301-C1 cells by RNA-Seq
3′/5′ RACE analyses of the SeMNPV gene transcripts
-
Although bioinformatics tools for sequence assembly and data analysis have been developed, the de novo assembly of short reads continues to be challenging in cases where there is no reference genome (Chen et al., 2014). In this study, we obtained 56, 865, 504 raw reads from Se301 cells and 54, 569, 296 raw reads from P8-Se301-C1 cells using RNA-Seq. Previous studies have obtained more than 34, 809, 334 raw reads associated with the S. exigua transcriptome and representing all the stages of the lifecycle of S. exigua comprising the egg, larval, pupal, and adult stages (Li et al., 2013) and 74, 928 raw reads associated with the gene expression of S. exigua larvae infected with AcMNPV (Choi et al., 2012). After assembly of the de novo transcripts from the P8-Se301-C1 and Se301 samples using Trinity software, a total of 112, 565 and 102, 996 final unigenes were generated, respectively. The set of final unigenes from the P8-Se301-C1 cells contained 26, 553 (23.6%) unigenes that were annotated and the final set of unigenes from the Se301 cells contained 24, 906 (24.2%) unigenes that were annotated. This additional data provides more genetic information for further studies of S. exigua.
In the P8-Se301-C1 cells, ten SeMNPV gene transcripts were detected by RNA-Seq. RACE analyses were carried out to analyze the full length of each of the ten gene transcripts, and six additional SeMNPV genes were detected during the RACE analyses. Thus, taken together, sixteen SeMNPV gene transcripts were identified in P8-Se301-C1 cells, comprising the full-length sequences of nine genes (se5, se7, se8, se12, se43, se45, se89, se124 and se126), and the partial sequences of seven genes (se11, se42, se44, se88, se90, se91 and se127).
se5 is a unique SeMNPV gene with unknown function. A bioinformatics analysis showed that it has five protein kinase C phosphorylation sites and nine casein kinase Ⅱ phosphorylation sites (Sun et al., 2015). Compared to the wild-type control, the deletion of se5 resulted in a decrease in the pathogenicity of occlusion bodies (OBs) and a significantly extended the viral life cycle. se7 is an early gene that is unnecessary for viral replication but required for efficient production of baculoviruses(de Jong et al., 2009). se8, which encodes F protein, has been found in group Ⅱ nucleopolyhedroviruses (NPVs). It is a functional homolog of the GP64 protein of group Ⅰ NPVs of alphabaculoviruses but has a higher rate of activitythan GP64 (Westenberg et al., 2007).
se11 is a closely related homolog of ld137a (orf4 PE) from Lymantria dispar multiple nucleopolyhedrovirus (LdMNPV), which encodes a protein that appears to be a major component of the polyhedron envelope (Gombart et al., 1989a; Russell & Rohrmann, 1990). se12 is a late gene expression factor that plays a direct role in very late gene transcription (Sriram and Gopinathan, 1998). se42 is the closely related homolog of ac19 from AcMNPV (IJkel et al., 1999). se44 is a unique SeMNPV gene with unknown function (IJkel et al., 1999). The homolog of se43 in AcMNPV is ac18, which is a highly conserved gene in lepidopteran nucleopolyhedroviruses. se43 may play a role in the efficiency of S. exigua infections (Wang et al., 2007).
In terms of protein identity and genomic location, the homolog of se45 in LdMNPV is ld120 (rr2b) (IJkel et al., 1999). se88 is a closely related homolog of ac71 (iap-2) from AcMNPV, which functions as an apoptosis inhibitor and is a potential host range factor (Li et al., 1999). The homolog of se89 in AcMNPV, ac69, has a stimulatory effect on late gene expression and has been implicated in cell division (Li et al., 1999). se90 is a baculovirus core gene that has been shown to be highly conserved in all baculoviruses that have been fully sequenced (Nie et al., 2012). It is homologous to ORF 56 (bm56) of B. mori nuclear polyhedrosis virus (BmNPV), which facilitate efficient virus production in vivo (Xu et al., 2008). se91 is a closely related homolog of ac67 (lef-3) from AcMNPV, which is essential for AcMNPV DNA replication in vivo (Yu and Carstens, 2012).
The se124 homologs are highly conserved in all sequenced alphabaculoviruses and its homolog in AcMNPV, Ac34, is an activator protein that promotes late gene expression and is essential for the pathogenicity of AcMNPV (Cai et al., 2012). se126 is a homolog of ORF16 (bm16) of BmNPV, which functions as a single-stranded DNA binding protein that plays a role in virus replication (Mikhailov et al., 1998). se127 is a closely related homolog of ac28 (lef-6) of AcMNPV, which is not essential for viral replication but the infection cycle is substantially delayed in its absence (Lin and Blissard, 2002).
Previously, a study demonstrated the presence of a SeMNPV polyhedrin transcript in P8-Se301-C1 cells (Weng et al., 2009). In this study, before RNA-Seq was carried out, the presence of the polyhedrin transcript was confirmed by nested RT-PCR using the total RNA extracted from the P8-Se301-C1 cells. However, the transcript was not identified from the RNA-Seq results. Six more transcripts (se11, se42, se44, se88, se91 and se127) were detected using RACE analyses, but not by RNA-Seq, which implies that more SeMNPV gene transcripts may be present in P8-Se301-C1 cells but were not identified due to their low abundance.
The RACE analyses of the full-length transcripts containing SeMNPV genes showed that the 3′ and 5′ end sequences of the transcripts map to B. mori genes or to unknown genes that cannot be aligned to sequences in the NCBI's Nucleotide Database. We also attempted to align the 3′ and 5′ end sequences to the previous sequence data on S. exigua (NCBI accession numbers: SRX110132, SRX110248, GAFU00000000 and SRA056289) (Choi et al., 2012; Li et al., 2013), but there were no matches. As the entire SeMNPV genome has been sequenced (IJkel et al., 1999), the 3′ and 5′ end must be from the host genome and not from the SeMNPV genome, suggesting that the SeMNPV genes integrate into host genome and are transcribed with the host genome in P8-Se301-C1 cells.
Latent infections of insect cells with nudivirus 1 (HzNV-1) is characterized by the expression of only one viral transcript (persistence associated transcript 1, PAT1) (Chao et al., 1992), and the viral DNA exists as either a circular or an inserted form (Lee and Lehman, 1999). In chronic hepatitis B virus (HBV) infections of humans, subgenomic HBV DNA fragments were found to integrate into random sites of the host genome (Bonilla and Roberts, 2005; Minami et al., 2005). Due to the integration, the host genome was altered (a "cis" effect) and the HBV genome was altered (a "trans" effect) (Bonilla and Roberts, 2005; Minami et al., 2005), which may led to the modulation of the expression of the human genes near the integration sites, followed by integration site-specific expression of the genes during hepatocarcinogenesis (Tamori et al., 2005). In our study, we found that SeMNPV genes were integrated into the host genome in the P8-Se301-C1 cells, which led to the production of novel fusion transcripts. The results support our previous findings (Weng et al., 2009) and further demonstrate that SeMNPV resides in P8-Se301-C1 cells as a latent infection.
In summary, we obtained fully assembled transcripts from S. exigua cells and identified sixteen transcripts of SeMNPV genes in P8-Se301-C1 cells. Among the SeMNPV gene transcripts, ten transcripts were detected using RNA-Seq and six additional transcripts were detected using RACE analyses. The findings suggest that, in Se301 cells that are latently infected with SeMNPV, some baculoviral genomic DNA fragments fuse together and integrate into the host genome, which leads to the production of novel chimeric fusion transcripts. The role of these novel fusion transcripts in latency in P8-Se301-C1 cells remains unclear. Future DNA sequencing studies would be useful to further explain the form of the viral DNA in the latently infected insect cells and the locations of the viral gene integration sites in the host genome. The findings provide important insights into the molecular mechanisms of baculovirus latent infections and superinfection exclusion.
-
The authors appreciate valuable thoughts and suggestions from Prof. Kai Yang and Dr. Wenbi Wu at State Key Laboratory of Biocontrol of Sun Yet-sen University. We also thank Hanquan Liang at Sun Yet-sen University for revisions. This research was funded by the National Natural Science Foundation of China (No. 31160378), the Science and Technology Foundation of Guizhou Province (No. LKS[2010]21), and the Startup Foundation for Doctors of Guizhou Normal University.
-
The authors declared that they have no conflict of interest. This article does not contain any studies with human or animal subjects performed by any of the authors.
-
QBW conceived and supervised the study, and finalized the manuscript. ZF performed most experiments and wrote the paper. JXS helped with the RACE experiments and manuscript drafting. All authors read and approved the final manuscript.
Supplementary figures/tables are available on the websites of Virologica Sinica: www.virosin.org; link.springer.com/journal/12250.
-
Primer Sequence (5'-3') Genome site (nt) Product size (bp) RT-PCR se5-F GCCTCTGCTATCGTTGCT 6832-6849 858 se5-R CTGATCGGTGGTTTCTCC 7689-7672 se7-F GAGGAGATACGAGGTGATG 9674-9692 753 se7-R TTTCCAAACTTTAGTGCC 10426-10409 se8-F CGCCAAAGACATAGTCCA 12557-12574 1736 se8-R GCGTCAACATTGCCATTA 14292-14275 se12-F TATAGCGTTCTGTTTAGCG 16124-16142 557 se12-R ATTGGATTGGTGCCTTTG 16680-16663 se43-F TCAGCGTCAATAGACTCAT 43066-43084 651 se43-R CGAAGCGATTCATAAAGTA 43716-43698 se45-F ACGACGACTTTACCCAGAA 44523-44541 656 se45-R ATCGGCGACAAACTCAAT 45178-45161 se89-F ACCAACGCCGATTGTCTG 86155-86138 566 se89-R GTGCGGTGGGCATCTTCA 85590-85607 se90-F AGGGACCGTGTCGAAGTA 86765-86748 301 se90-R CTGCCACCGTCAATAGGA 86465-86482 se124-F GGTTGGGTGACGTGATAC 118937-118954 413 se124-R GTCGCTACATTCGTAGTTGT 119349-119330 se126-F TGGGATACTCAAGCCTAAA 121203-121221 533 se126-R TCTCGCTCACCTTCTTATT 121737-121756 RACE-PCR - - GSP-se5-F CAAGAGGAGCCCTGGAAC - - GSP-se5-R GTGGAGGTAGAATACGGC - - GSP-se7-F GAGGAGATACGAGGTGATG - - GSP-se7-R CCGTGATTTCAAACCTTT - - GSP-se8-F CGCCAAAGACATAGTCCA - - GSP-se8-R ATTACCGTTACAACTGCG - - GSP-se12-F AGCGACATACCGTTGCAAGT - - GSP-se12-R GGCGATGTACGCGTTGAAAA - - GSP-se43-F CACCTTCGCCCTCAACAGAT - - GSP-se43-R AGCGCGTACAGAATGCTCTT - - GSP-se45-F TGTCTGCCGCACGAAAAGTA - - GSP-se45-R CTAAACGTCAGTCCGGGCAT - - GSP-se89-F CCGGCCAGTTTGCCAAATAC - - GSP-se89-R TCGTTTCCGCTAACGTCGAA - - GSP-se124-F CCAAAATCCCGACGACAACG - - GSP-se124-R GGTCGCGCATCATCATCAAC - - GSP-se126-F CGTTTCTGCGCGAATCTCTG - - GSP-se126-R TTGATCGCGAGCGAATACGA - - NGSP-se5-F TGATTTCGATGGCCTACCCG - - NGSP-se5-R TTTCCGGTCTGTCATCAGGC - - NGSP-se7-F AGCGCAGAACCGTATGTCAA - - NGSP-se7-R TCTCGTCTCGGTGACCGTAT - - NGSP-se8-F GTGCCGCATGAGCGATAAAG - - NGSP-se8-R TCGCTTTCGAACCTACCCAC - - NGSP-se12-F GAAGCGTTGACGCCGAAAAA - - NGSP-se12-R GCGCGGACGAACTTGAAAAT - - NGSP-se43-F GATTGCAGCCGTTCAAGAGC - - NGSP-se43-R CCCAAGGTGTACGTGTCGAT - - NGSP-se45-F CAGGCGTTGGATTGCATGTG - - NGSP-se45-R TTGACTATACTGTCGGCGGC - - NGSP-se89-F GGCGTCACCTTACGAGACAA - - NGSP-se89-R TGTCGAAGCAGCCGTACATT - - NGSP-se124-F CCGCCGTTAAACAACCATCG - - NGSP-se124-R TCTCCAAGACGACACTCCCA - - NGSP-se126-F GAGCATTCGTTGGTCGAAGC - - NGSP-se126-R AGAACTTGCGCACAAACGTC - - Table S1. Names and sequences of the primers used for the RT-PCR and 5'/3' RACE-PCR
Cell line Raw reads Quality trimmed Adaptor trimmed rRNA trimmed Clean ratio P8-Se301-C1 54, 569, 296 54, 292, 372 53, 666, 292 52, 784, 058 96.7% Se301 56, 865, 504 56, 639, 360 55, 941, 000 55, 033, 958 96.8% Table S2. Statistical results of the stringent filtering processes
Cell line Counts Total length (nt) N50 (nt) Mean length N% GC% P8-Se301-C1 116, 048 136, 121, 302 2, 137 1, 173 0.0 37.5 Se301 104, 600 122, 303, 958 2, 145 1, 169 0.0 37.6 Table S3. Statistical results concerning the primary unigenes from P8-Se301-C1 and Se301 cells
Cell line Counts Total length (nt) N50 (nt) Mean length N% GC% P8-Se301-C1 112, 565 121, 964, 401 1, 824 1, 093 0.0 37.3 Se301 102, 996 109, 124, 144 1, 803 1, 082 0.0 37.4 Table S4. Statistical results concerning the final unigenes from P8-Se301-C1 and Se301 cells

Figure S1. (A) The distribution of the lengths of the final unigenes from P8-Se301-C1 cells. (B) The distribution of the lengths of the final unigenes from Se301 cells.
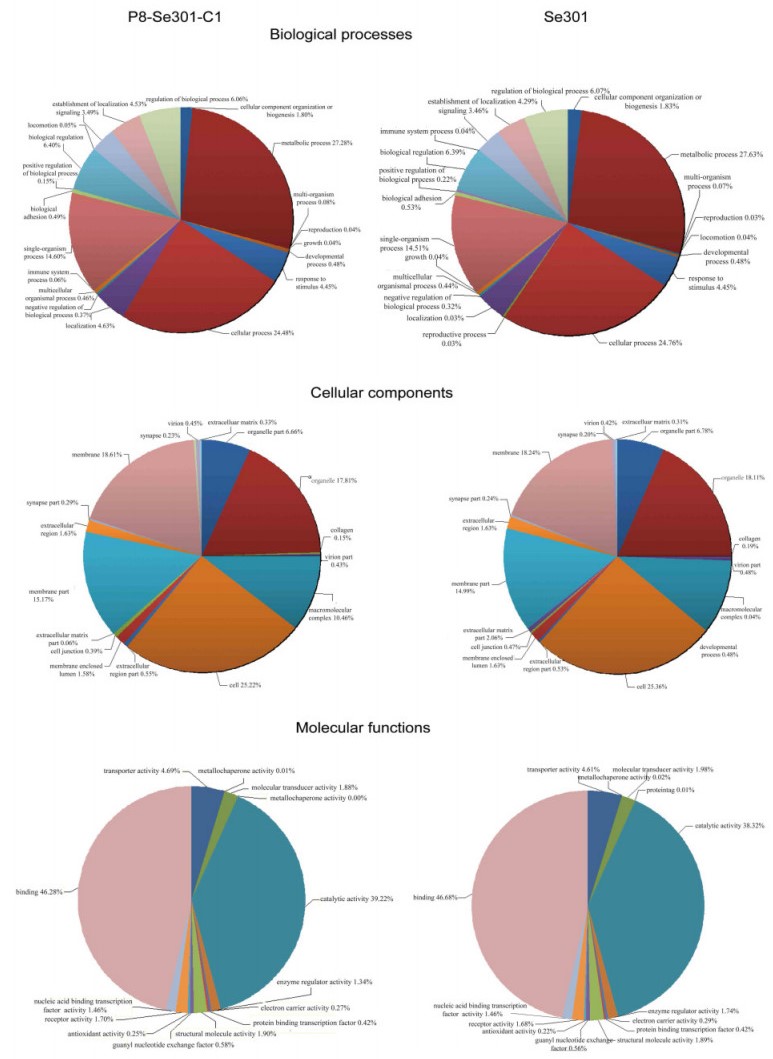
Figure S2. Gene ontology (GO) classification, including cellular components, biological processes, and molecular functions.

Figure S3. The full-length transcripts containing (A) se5, (B) se7, (C) se8, (D) se12, (E) se43, (F) se45, (G) se89, (H) se124 and (I) se126. The sequences that align to the SeMNPV genome are presented in blue and the sequences that align with the host genome are presented in black.


 DownLoad:
DownLoad: